

هدف DevOps تسریع فرآیند توسعه، اطمینان از تستهای منظم و تسهیل انتشارهای مکرر است، در حالی که کیفیت را بهبود میبخشد و هزینهها را کاهش میدهد. برای دستیابی به این اهداف، ابزارهای مانیتورینگDevOps، اتوماسیون و قابلیتهای اندازهگیری و نظارت پیشرفتهای را در طول چرخه عمر توسعه ارائه میدهند که شامل برنامهریزی، توسعه، یکپارچهسازی، تست، استقرار و عملیات میشود.
چرخه عمر توسعه نرمافزار امروزی سریعتر از همیشه است و مراحل مختلف توسعه و تست بهطور همزمان انجام میشوند. این تحول منجر به ظهور DevOps شده است که تیمهای جداگانهای که مسئولیت توسعه، تست و عملیات را داشتند، به یک واحد منسجم تبدیل میکند که تمامی وظایف را انجام میدهد و اصول “شما آن را میسازید، شما آن را اجرا میکنید” (YBIYRI) را پذیرفته است.
با توجه به تغییرات مکرر در کد، تیمهای توسعه برای دستیابی به دیدگاهی کامل و در زمان واقعی از محیط تولید، نیاز به پایش DevOps دارند.
مانیتورینگ DevOps چیست؟
مانیتورینگ DevOps نظارت جامع بر چرخه عمر توسعه را شامل میشود که مراحل برنامهریزی، توسعه، یکپارچهسازی، تست، استقرار و عملیات را در بر میگیرد. این فرآیند یک دیدگاه جامع و در زمان واقعی از عملکرد برنامهها، خدمات و زیرساختها در محیط تولید ارائه میدهد. ویژگیهای اساسی مانند جریان دادههای لحظهای، تحلیل تاریخی و نمایشهای بصری نقش مهمی در مانیتورینگ برنامهها و خدمات ایفا میکنند. مهندسان اغلب از اصطلاحات “مانیتورینگ مستمر” (Continuous Monitoring – CM) و “مانیتورینگ کنترل مستمر” (Continuous Control Monitoring – CCM) برای توصیف این فرآیند استفاده میکنند، با این حال مفهوم اساسی بدون تغییر باقی میماند.
در DevOps، فرآیند بهصورت یک چرخهی پیوسته دنبال میشود. این چرخه شامل مراحل برنامهریزی، توسعه، یکپارچهسازی، تست، استقرار و عملیات است.
اجرای DevOps ممکن است نیازمند تلاش و دقت زیادی باشد، اما مزایای آن ارزش این تلاش را دارد.
برخی از مزایای مانیتورینگ DevOps عبارتند از:
- تعریف، ردیابی و اندازهگیری شاخصهای کلیدی عملکرد (KPI) در تمامی جنبههای DevOps.
- افزایش قابلیت مشاهده (observability) اجزای مختلف DevOps بهمنظور شناسایی کاهش در عملکرد، امنیت، هزینه یا سایر جنبهها.
- شناسایی و گزارش سریع ناهنجاریها به تیمهای مربوطه، تا مشکلات پیش از تأثیرگذاری بر تجربه کاربری حل شوند.
- تحلیل لاگها و متریکها برای کشف سریعتر علل ریشهای. ردیابی لاگها و متریکها میتواند به شناسایی محل شروع یا وقوع یک مشکل کمک کند. به همین دلیل، میانگین زمان تشخیص (MTTD)، میانگین زمان ایزولهسازی (MTTI)، میانگین زمان تعمیر (MTTR) و میانگین زمان بازیابی (MTTR) بهبود پیدا میکند.
- پاسخ به تهدیدات بهصورت آنکال یا خودکار با استفاده از ابزارهای مختلف.
- یافتن فرصتهایی برای اتوماسیون در طول فرآیند DevOps که بهبود زنجیره ابزارهای DevOps و کارایی مهندسان را به همراه دارد.
- شناسایی الگوهای رفتاری سیستم که یک مهندس DevOps باید در آینده به آنها توجه داشته باشد.
- ایجاد یک حلقه بازخورد مستمر که همکاری بین مهندسان، کاربران (داخلی و خارجی) و سایر بخشهای سازمان را بهبود میبخشد.
- با نظارت بر عملیات DevOps، یک سازمان میتواند تجربههای عالی برای مشتریان فراهم کند و همزمان هزینهها را در سراسر چرخه عمر DevOps کاهش دهد.
چرا مانیتورینگ DevOps مهم است؟
برای بهبود جنبههایی مانند توازن بار و امنیت، یا برای توسعه ابزارهای فرآیندی جهت پروتکلهای بازگشت (rollback) و زیرساختهای خودترمیمشونده، مانیتورینگ مؤثر بسیار ضروری است تا بتوانید دیدگاههای دقیقی نسبت به برنامهها و زیرساختهای خود به دست آورید. مانیتورینگ DevOps یک راهکار جامع و کاربرپسند ارائه میدهد که دیدگاهها را سادهتر میکند و به همین دلیل، هم فرآیند تحویل نرمافزار و هم کیفیت محصول نهایی را بهبود میبخشد.
مانیتورینگ DevOps نقش حیاتی در حفظ عملکرد و امنیت سیستمهای فناوری اطلاعات ایفا میکند. اما اهمیت آن به همین موارد محدود نمیشود. در ادامه دلایل دیگری که مانیتورینگ DevOps را ضروری میسازند، آورده شده است:
پیگیری عملکرد بهبود یافته
مانیتورینگ DevOps به تیمها این امکان را میدهد که بهطور مداوم و دقیق عملکرد برنامهها و زیرساختها را زیر نظر داشته باشند. این امر موجب میشود که هر گونه مشکل به سرعت شناسایی و رفع گردد. علاوه بر این، اطمینان مستمر از بهبود کارایی سیستم و رضایت کاربران فراهم میآید.
بهینهسازی هزینهها
ابزارهای DevOps به نظارت بر استفاده از منابع و شناسایی فرصتهای صرفهجویی در هزینهها کمک میکنند. با تحلیل اثرات اجزا و فرآیندهای مختلف، سازمانها میتوانند هزینهها را کاهش داده و مدیریت مالی خود را بهبود بخشند.
تشخیص پیشگیرانه ناهنجاریها
تیمهای DevOps قادر به شناسایی ناهنجاریها در مراحل اولیه با نظارت بر شاخصهای کلیدی و لاگها هستند، که به جلوگیری از تأثیر منفی بر کاربران نهایی کمک میکند. با اجرای استراتژیهای پیشگیرانه، میتوانند زمانهای غیرقابل دسترس بودن را به حداقل رسانده و قابلیت اطمینان برنامهها را افزایش دهند.
همکاری بهبود یافته
مانیتورینگ مداوم موجب تقویت همکاری بین تیمهای توسعه و عملیات میشود. با تبادل بینشها و دادهها، این تیمها میتوانند به چالشها پرداخته و کارایی را بهبود بخشند. این امر منجر به جریان کاری روانتر و پربارتر میشود.
بهبود مستمر
مانیتورینگ در DevOps بینشهای اساسی را ارائه میدهد که میتواند به بهینهسازی شیوههای DevOps کمک کند. با بررسی روندهای عملکرد، تیمها میتوانند کارایی و اثربخشی عملیات خود را افزایش دهند.
رفع سریع مشکلات
مانیتورینگ مداوم به تیمها این امکان را میدهد که مشکلات را به سرعت شناسایی کرده و فرآیند حل آنها را تسریع کنند. این رویکرد همچنین مدت زمان مورد نیاز برای بازگشت به وضعیت عادی را به حداقل میرساند.
تصمیمگیری بهتر
بینشهای حاصل از ابزارهای مانیتورینگ به تصمیمگیری آگاهانه کمک میکند. تیمها این دادهها را برای شناسایی وظایف اولویتدار و تخصیص مؤثر منابع ارزیابی میکنند.
تجربه کاربری بهبود یافته
با حفظ مانیتورینگ منظم، تیمهای DevOps میتوانند تجربهای یکپارچه و مثبت برای کاربران نهایی فراهم کنند. این شامل اطمینان از حفظ زمانهای پاسخ بهینه، در دسترس بودن بالا و عملکرد قابل اعتماد خدمات است.
امنیت و تطابق
مانیتورینگ در DevOps شامل ارزیابی شاخصهای امنیتی و ارزیابی تطابق با استانداردهای صنعتی است. این فرآیند به شناسایی آسیبپذیریها و اطمینان از محیط IT امن کمک میکند. علاوه بر این، نقش مهمی در حفاظت از اطلاعات حساس و حفظ اعتماد کاربران ایفا میکند.
مانیتورینگ DevOps در مقایسه با قابلیت مشاهده (Observability)
وقتی که به سمت چپ حلقه بینهایت به عنوان سمت محصول و سمت راست آن به عنوان سمت عملیات نگاه میکنیم، مدیر محصول مسئول راهاندازی ویژگی جدید به تولید، بر چگونگی تقسیم پروژه به وظایف و داستانهای کاربری تمرکز میکند. توسعهدهنده در سمت چپ باید فرآیند استقرار ویژگی را درک کند که شامل مدیریت بلیتهای پروژه، داستانهای کاربری و وابستگیها است. علاوه بر این، اگر توسعهدهندگان به اصل DevOps “شما آن را میسازید، شما آن را اجرا میکنید” پایبند باشند، باید به رفع مشکلات نیز توجه داشته باشند.
با گذر از جنبه عملیاتی چرخه عمر، یک مهندس قابلیت اطمینان سایت (SRE) باید خدماتی را که مشمول اندازهگیری و مانیتورینگ هستند درک کند تا بتواند بهطور سریع مشکلات پیشآمده را حل کند. بدون یک ابزار DevOps یکپارچه که این فرآیندها را ادغام کند، محیط ممکن است دچار بینظمی و آشفتگی شود. برعکس، یک زنجیره ابزار یکپارچه به بینش بهتری از فعالیتهای جاری ارائه میدهد.
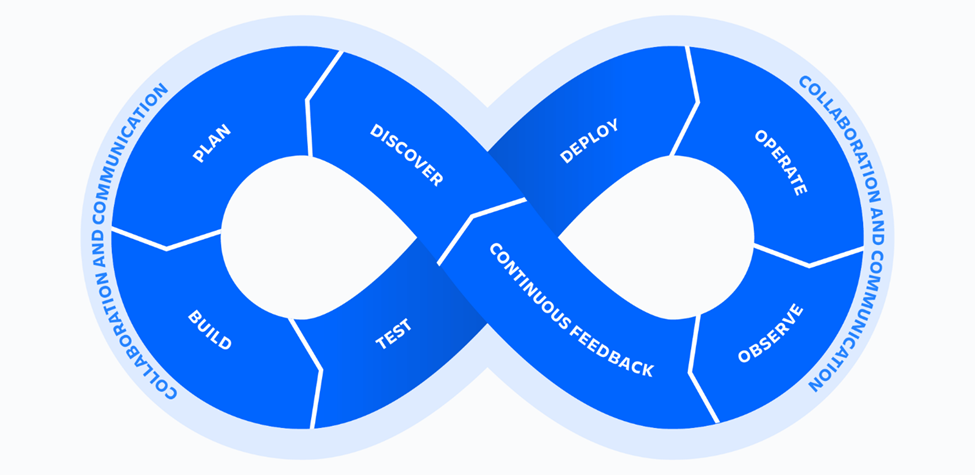
انواع مانیتورینگ در DevOps: چه چیزهایی باید مانیتور شوند؟
مانیتورینگ در DevOps نقش مهمی در خودکارسازی فرآیندها در طول چرخه توسعه نرمافزار ایفا میکند. هدف اصلی آن بهبود شفافیت، عملکرد و تجربه کلی کاربران در محیطهای IT است. استراتژیهای مختلف مانیتورینگ در DevOps برای نظارت بر اجزای سختافزاری و نرمافزاری، راهحلهای ذخیرهسازی، سرورها و موارد دیگر وجود دارد. این استراتژیها شامل موارد زیر است:
- مانیتورینگ زیرساختها
- مانیتورینگ عملکرد برنامهها (APM)
- مانیتورینگ شبکه
- مانیتورینگ لاگها
- مانیتورینگ امنیت
- مانیتورینگ مصنوعی
- مانیتورینگ هزینهها
۱. مانیتورینگ زیرساختها
هدف:
نظارت بر زیرساختها به نظارت بر سلامت و عملکرد منابع سختافزاری اساسی که زیرساخت برنامهها را تشکیل میدهند، مانند سرورها، سیستمهای ذخیرهسازی، دستگاههای شبکه و دیتاسنترها، اختصاص دارد. این روش نظارت تضمین میکند که اجزای فیزیکی و مجازی بهطور مؤثر عمل کنند و مشکلات بالقوه پیش از آنکه بر عملکرد برنامهها تأثیر بگذارند، بهطور زودهنگام شناسایی شوند.
حوزههای کلیدی:
- سرورها: نظارت بر استفاده از CPU، میزان استفاده از حافظه، I/O دیسک، و زمان فعال بودن سیستم.
- دستگاههای شبکه: نظارت بر روترها، سوئیچها، و سایر اجزای شبکه برای بررسی تأخیر، از دست رفتن بستهها، و استفاده از پهنای باند.
- ذخیرهسازی: نظارت بر فضای دیسک، سرعتهای خواندن/نوشتن، و عملکرد پایگاههای داده.
شاخصهای کلیدی:
- استفاده از CPU: استفاده بالای CPU میتواند نشاندهنده بار زیاد بر روی سرور یا برنامهای باشد که نیاز به بهینهسازی دارد.
- استفاده از حافظه: نظارت بر استفاده از حافظه به شناسایی نشتهای حافظه یا منابع ناکافی کمک میکند.
- I/O دیسک: نظارت بر ورودی/خروجی دیسک اطمینان میدهد که سیستمهای ذخیرهسازی تحت فشار نباشند، که میتواند باعث کندی برنامهها شود.
- تأخیر شبکه: این معیار زمان لازم برای انتقال دادهها از یک نقطه به نقطه دیگر را اندازهگیری میکند که برای اطمینان از ارتباط روان بین سیستمها حیاتی است.
دو نوع مانیتورینگ زیرساختها وجود دارد:
- مانیتورینگ زیرساختها با استفاده از عامل: در این روش، مهندسان یک عامل (نرمافزار) را بر روی هر یک از میزبانهای خود، چه فیزیکی و چه مجازی، نصب میکنند. این عامل اطلاعات مربوط به زیرساخت را جمعآوری کرده و به ابزار نظارتی برای تجزیه و تحلیل و نمایش ارسال میکند.
- مانیتورینگ زیرساختها بدون عامل: در این روش، نیازی به نصب عامل نیست. در عوض، از پروتکلهای داخلی مانند SSH، NetFlow، SNMP و WMI برای ارسال شاخصهای مربوط به اجزای زیرساخت به ابزارهای نظارتی استفاده میشود.
هر روش مزایا و معایب خاص خود را دارد. نظارت با استفاده از عامل، به عنوان مثال، اطلاعات دقیقتری جمعآوری میکند زیرا به دستگاه یا اجزای مورد نظر شما اختصاص دارد. از سوی دیگر، مهاجرت به یک پلتفرم مختلف ممکن است مشکلات سازگاری با عامل ایجاد کند که میتواند منجر به از دست رفتن دادهها شود. علاوه بر این، عاملها میتوانند منابع قابل توجهی از سرورهای شما را مصرف کنند که منجر به افزایش تأخیر یا هزینههای اضافی میشود.
عناصر مختلف زیرساخت، مانند ماشینهای مجازی (از جمله Hyper-V و VMware)، سرورها، تجهیزات شبکه، راهحلهای ذخیرهسازی و دستگاههای جریان، ویژگیهای نظارت بدون عامل یکپارچهای را ارائه میدهند. علاوه بر این، میتوانید نظارت بر این اجزا را از یک مکان متمرکز مدیریت کنید. با ادغام هر دو روش، میتوانید استراتژی مانیتورینگ قویتری توسعه دهید.
یک ابزار مؤثر مانیتورینگ زیرساخت باید قادر به انجام مسئولیتهای زیر باشد:
- مانیتورینگ دسترسی سرورها: ابزارهای نظارت بر زیرساختها برای DevOps باید قادر به مشاهده و نظارت بر دسترسی سرورها باشند.
- پیگیری استفاده از CPU و دیسک: ابزارهای مانیتورینگ زیرساختها باید توانایی پیگیری استفاده از CPU و دیسک را داشته باشند تا مشکلاتی که عملکرد سیستم را مختل میکنند، تحلیل شوند.
- نمایش قابلیت اطمینان و مقاومت سیستم: ابزارهای نظارت بر زیرساختها باید توانایی نمایش میزان قابلیت اطمینان و مقاومت سیستم را از طریق پیگیری و نظارت بر زمان اجرای آن داشته باشند.
- پیگیری زمان پاسخدهی سیستم: ابزار مانیتورینگ زیرساخت باید قادر به پیگیری زمان پاسخدهی سیستم در صورت بروز خطا باشد.
ابزارهای DevOps برای مانیتورینگ زیرساختها: Nagios، Prometheus، Zabbix.
۲. مانیتورینگ عملکرد برنامهها (APM)
هدف:
APM به نظارت بر عملکرد و دسترسی برنامههای نرمافزاری اختصاص دارد تا اطمینان حاصل شود که بهطور مطلوب عمل میکنند. این نظارت برای شناسایی و رسیدگی به مشکلات مرتبط با عملکرد برنامه، تجربه کاربری و دسترسی کلی بسیار حیاتی است.
حوزههای کلیدی:
- تجربه کاربری: نظارت بر تعاملات کاربران با برنامه برای اطمینان از اینکه تجربهای روان و بدون خطا دارند.
- ردیابی تراکنشها: پیگیری جریان تراکنشها در بین اجزای مختلف برنامه برای شناسایی گلوگاهها.
- وابستگیهای برنامه: نظارت بر خدمات یا APIهای شخص ثالثی که برنامه به آنها وابسته است تا اطمینان حاصل شود که بهدرستی عمل میکنند.
ابزارهای مانیتورینگ عملکرد برنامه عمدتاً شاخصهای زیر را پیگیری میکنند:
- زمان پاسخدهی: اندازهگیری زمان لازم برای اینکه برنامه به درخواست کاربر پاسخ دهد.
- نرخ خطا: پیگیری تعداد خطاهای رخ داده در داخل برنامه، که میتواند نشاندهنده مشکلاتی در کد یا زیرساختهای اصلی باشد.
- تراکم: تعداد تراکنشها یا درخواستهایی که برنامه در یک بازه زمانی معین پردازش میکند.
- دسترسپذیری برنامه: اطمینان از اینکه برنامه در دسترس و قابل استفاده برای کاربران است.
نظارت بر عملکرد برنامه به تیمها این امکان را میدهد تا مشکلات را بهطور پیشگیرانه شناسایی و برطرف کنند، پیش از آنکه بر عملکرد برنامه تأثیر بگذارد. ابزارهای نظارت بر برنامه معمولاً به ارزیابی پاسخهای API، مدت و حجم تراکنشها، پاسخهای سیستم و سلامت کلی برنامه میپردازند.
یک پلتفرم ایدهآل برای مانیتورینگ برنامه باید قادر به انجام موارد زیر باشد:
- ارائه ادغام بومی با ابزارهای استفادهشده در فرآیند توسعه.
- فراهم کردن دسترسی به دادههای زمان واقعی برای شناسایی و رفع سریع مشکلات و گلوگاهها.
- بهبود و تأمین امنیت ارتباطات داخلی دادهها و ایجاد کنترلهای امنیتی قوی.
- تولید گزارشها و داشبوردهای کاربرپسند.
- ارائه روندهای تاریخی رویدادها و همبستگیهای آنها برای شناسایی ریسکهای پنهان.
ابزارهای DevOps برای مانیتورینگ برنامه: Datadog، Splunk، AppDynamics، New Relic، Dynatrace.
۳. مانیتورینگ شبکه
هدف:
مانیتورینگ شبکه شامل نظارت بر عملکرد و دسترسی اجزای مختلف شبکه از جمله روترها، سوئیچها، فایروالها و اتصالات است. این فرآیند برای حفظ زیرساخت شبکهای قابلاطمینان که نیازهای ارتباطی برنامهها را برآورده کند، ضروری است. ابزارهای نظارت بر شبکه برای شناسایی مشکلات عملکردی درون شبکه از طریق ارزیابی اجزای کلیدی آن اهمیت دارند. این فرآیند شامل تحلیل و پیگیری معیارهای حیاتی است.
- تأخیر (Latency): اندازهگیری تأخیر در انتقال دادهها در شبکه که برای برنامههای نیازمند ارتباطات بلادرنگ حیاتی است.
- از دست رفتن بستهها (Packet Loss): نشاندهنده درصد بستههای دادهای است که به مقصد نمیرسند و میتواند منجر به کاهش عملکرد برنامه شود.
- تراکم شبکه (Network Throughput): میزان دادهای که بهطور موفقیتآمیز از یک نقطه به نقطه دیگر در شبکه در یک بازه زمانی معین منتقل میشود.
- دسترسپذیری دستگاهها (Device Availability): نظارت بر اینکه آیا دستگاههای شبکه مانند روترها و سوئیچها آنلاین هستند و بهدرستی عمل میکنند.
این معیارها به اندازهگیری و اصلاح مشکلات شبکه کمک میکنند.
مانیتورینگ شبکه شامل پنج فرآیند کلیدی است: کشف، تعیین حدود، شناسایی، مشاهده و گزارشگیری. از طریق این فرآیندها، نظارت بر شبکه به سیستمهای IT این امکان را میدهد که بهطور پیشگیرانه مشکلات را شناسایی کنند. علاوه بر این، به بهبود عملکرد و دسترسی اجزای تحت نظارت کمک میکند.
حوزههای کلیدی:
- تأخیر شبکه (Network Latency): مانیتورینگ زمان لازم برای انتقال دادهها بین دو نقطه در شبکه.
- استفاده از پهنای باند (Bandwidth Usage): پیگیری میزان دادهای که در شبکه منتقل میشود، که به شناسایی انسداد یا کمبودهای بالقوه پهنای باند کمک میکند.
- از دست رفتن بستهها (Packet Loss): نظارت بر درصد بستههای دادهای که در حین انتقال از دست میروند و میتواند بر عملکرد برنامه تأثیر بگذارد.
- زمان آنلاین/آفلاین (Uptime/Downtime): اطمینان از اینکه دستگاههای شبکه آنلاین و بهدرستی عمل میکنند.
ابزارهای DevOps برای نظارت بر شبکه: Wireshark، Nmap (Network Mapper)، SolarWinds Network Performance Monitor، Nagios.
۴. مانیتورینگ لاگها
هدف:
مانیتورینگ لاگها شامل بررسی و نظارت بر فایلهای لاگی است که توسط برنامهها و زیرساختها تولید میشود. این لاگها مستندات جامعی از رویدادها، خطاها، تراکنشها و تعاملات کاربران را ارائه میدهند و به همین دلیل ابزار ضروری برای عیبیابی و نظارت امنیتی محسوب میشوند.
حوزههای کلیدی:
- لاگهای خطا (Error Logs): نظارت بر لاگهای خطا کمک میکند تا مشکلات موجود در برنامه یا سیستم به سرعت شناسایی و رفع شوند.
- لاگهای دسترسی (Access Logs): این لاگها پیگیری میکنند که چه کسی به سیستم دسترسی پیدا کرده و از کجا، که برای ممیزیهای امنیتی و تحلیل رفتار کاربران مفید است.
- لاگهای رویداد (Event Logs): رویدادهای مهم سیستم مانند تغییرات پیکربندی، شکستها و نقضهای امنیتی را ثبت میکند.
شاخصهای کلیدی:
- حجم لاگها (Log Volume): نظارت بر حجم لاگها به شناسایی فعالیتهای غیرعادی، مانند افزایش ناگهانی در خطاها یا تلاشهای دسترسی، کمک میکند.
- فرکانس خطا (Error Frequency): خطاهای مکرر در لاگها میتواند نشاندهنده مشکلات تکراری باشد که نیاز به توجه دارند.
- ناهنجاریهای لاگ (Log Anomalies): الگوهای غیرعادی در لاگها، مانند تلاشهای ورود غیرمنتظره یا رویدادهای غیرعادی سیستم، میتواند نشاندهنده نقضهای امنیتی یا مشکلات سیستمی باشد.
ابزارها: ELK Stack (Elasticsearch، Logstash، Kibana)، Splunk، Graylog.
۵. مانیتورینگ ایمنی
هدف:
مانیتورینگ امنیت شامل مشاهده و ارزیابی فعالیتهای مرتبط با امنیت در برنامهها، شبکهها و زیرساختها است. این فرآیند برای شناسایی تهدیدات بالقوه، شناسایی نقضها و حفظ تطابق با سیاستهای امنیتی ضروری است.
حوزههای کلیدی:
- شناسایی نفوذ (Intrusion Detection): نظارت برای دسترسی غیرمجاز یا فعالیتهای مشکوک درون سیستم.
- اسکن آسیبپذیری (Vulnerability Scanning): شناسایی و پیگیری آسیبپذیریها درون سیستم که ممکن است توسط مهاجمان مورد سوءاستفاده قرار گیرد.
- نظارت بر فعالیتهای کاربران (User Activity Monitoring): پیگیری اقدامات کاربران برای اطمینان از تطابق با سیاستهای امنیتی و شناسایی تهدیدات داخلی احتمالی.
شاخصهای کلیدی:
- رویدادهای امنیتی (Security Incidents): تعداد و نوع نقضهای امنیتی یا حوادث شناسایی شده.
- لاگهای دسترسی کاربران (User Access Logs): نظارت بر اینکه چه کسی به چه منابعی دسترسی پیدا کرده و کی، که برای پیگیریهای حسابرسی و شناسایی دسترسیهای غیرمجاز حیاتی است.
- امتیازهای آسیبپذیری (Vulnerability Scores): شاخصهایی که شدت و تأثیر آسیبپذیریهای شناسایی شده درون سیستم را نشان میدهند.
ابزارها: Snort، Splunk، OSSEC.
ابزارها: Pingdom، New Relic Synthetic Monitoring، Catchpoint.
۶. مانیتورینگ مصنوعی
هدف:
مانیتورینگ مصنوعی تعاملات کاربران با برنامهها یا وبسایتها را شبیهسازی میکند تا عملکرد و دسترسی آنها را از دیدگاه خارجی ارزیابی کند. این استراتژی پیشگیرانه به تیمها این امکان را میدهد که مشکلات را شناسایی و برطرف کنند پیش از آنکه بر روی کاربران واقعی تأثیر بگذارد.
حوزههای کلیدی:
- آزمایش تراکنشها (Transaction Testing): شبیهسازی تراکنشها برای اطمینان از عملکرد صحیح آنها، مانند فرآیندهای ورود به سیستم یا دروازههای پرداخت.
- زمانهای بارگذاری صفحات (Page Load Times): اندازهگیری زمان لازم برای بارگذاری یک صفحه وب تحت شرایط شبیهسازی شده.
- آزمایش API (API Testing): شبیهسازی تماسهای API برای اطمینان از پاسخدهی صحیح و در بازه زمانی قابلقبول.
شاخصهای کلیدی:
- زمانهای پاسخدهی (Response Times): اندازهگیری سرعت پاسخگویی برنامه یا وبسایت به تعاملات شبیهسازی شده.
- نرخ خطاها (Error Rates): شناسایی فراوانی و نوع خطاهای encountered در طول آزمایشهای شبیهسازی شده.
- دسترسپذیری (Availability): پیگیری اینکه آیا برنامه یا وبسایت از مکانهای جغرافیایی مختلف در حال اجرا و در دسترس است.
ابزارها: Pingdom، New Relic Synthetic Monitoring، Catchpoint.
۷. مانیتورینگ هزینهها
پیگیری هزینهها در طول خط لوله DevOps برای جلوگیری از تجاوز از محدودیتهای بودجه ضروری است. این کار شامل ارزیابی استفاده از منابع میشود.
علاوه بر تجزیه و تحلیل زمان واقعی، راهحلهای پیشرفته مدیریت هزینه میتوانند اطلاعات دقیقی از هزینهها بهصورت واحدی و بر اساس مشتری یا پروژه ارائه دهند، که همکاری با دپارتمانهای مهندسی و مالی را برای اقدامات مورد نیاز بهبود میبخشد.
این قابلیت به شما بینش کاملی از هزینههای کالاهای فروخته شده (COGS)، حاشیههای سود ناخالص، و استفاده از منابع در هر مرحله از جریان کار DevOps ارائه میدهد.
رویکردهای مختلف نظارت اجزای ضروری استراتژی DevOps هستند که هرکدام به جنبههای خاصی از عملکرد سیستم، قابلیت اطمینان و امنیت هدف میزنند. با پیادهسازی مؤثر این تکنیکهای نظارتی، تیمهای DevOps میتوانند اطمینان حاصل کنند که برنامهها و زیرساختهایشان بهخوبی عمل میکنند، مشکلات را بهطور پیشگیرانه شناسایی و برطرف کنند و تجربه کلی کاربری را بهبود بخشند.
معیارهایی که باید با ابزارهای مانیتورینگ DevOps پیگیری کنید
در DevOps، مانیتورینگ شامل پیگیری معیارهای حیاتی برای اطمینان از عملکرد بهینه سیستم، قابلیت اطمینان و امنیت است. در زیر تعدادی از معیارهای مهم که باید به آنها توجه کنید، آورده شده است:
استفاده از CPU: پیگیری استفاده از CPU اهمیت زیادی دارد زیرا بینشهای مهمی از قدرت پردازشی مورد استفاده توسط برنامههای شما ارائه میدهد. استفاده بالا از CPU میتواند نشانهای از مشکلات عملکردی باشد که نیاز به مداخله فوری دارد. از طرف دیگر، استفاده پایین ممکن است نشاندهنده عدم بهرهبرداری کامل از منابع و فرصتی برای بهینهسازی باشد.
استفاده از حافظه: نظارت بر استفاده از حافظه تنها یک مسئولیت روتین نیست، بلکه وظیفهای ضروری است. این فرآیند کلیدی برای شناسایی نشتهای حافظه و اطمینان از این است که برنامهها منابع کافی برای عملکرد بهینه دارند. استفاده بیش از حد از حافظه میتواند منجر به کاهش عملکرد و احتمالاً خرابی سیستم شود.
دادههای لاگ: تحلیل دادههای لاگ برای کسب بینش در مورد عملکرد برنامهها و سیستمها ضروری است. از طریق نظارت بر لاگها، میتوان روندها را شناسایی کرد، مشکلات را حل نمود و رعایت پروتکلهای امنیتی را حفظ کرد.
ترافیک شبکه: نظارت بر ترافیک شبکه برای درک حرکت دادهها در زیرساخت شما حیاتی است. این روش به شناسایی مشکلات پهنای باند و تهدیدات احتمالی شبکه کمک میکند و همچنین به بهبود کارایی فرآیندهای انتقال دادهها میپردازد.
ورودی/خروجی دیسک (Disk I/O): معیارهای Disk I/O اطلاعات ارزشمندی در مورد عملیات خواندن و نوشتن دستگاههای ذخیرهسازی شما ارائه میدهند. پیگیری این معیارها میتواند به شناسایی مشکلات عملکردی مربوط به ذخیرهسازی، از جمله مشکلات با تأخیر و توان عملیاتی، کمک کند.
تاخیر خدمات (Service Latency): پیگیری تاخیر خدمات کمک میکند تا تأخیرهای ارتباطی در برنامه شما شناسایی شود. افزایش تأخیر میتواند به طور منفی بر عملکرد کلی و رضایت کاربران تأثیر بگذارد.
نرخ خطاها (Error Rates): پیگیری نرخ خطاها برای شناسایی مشکلات در جریان کار شما ضروری است. افزایش قابل توجه در خطاها ممکن است نشاندهنده مشکلات در پیادهسازی یا اشتباهات پیکربندی باشد.
استفاده از منابع (Resource Use): پیگیری استفاده از منابع به درک بهتر از نحوه تخصیص مؤثر منابع زیرساخت شما کمک میکند. این فرآیند شامل نظارت بر استفاده از CPU، حافظه، فضای دیسک و پهنای باند شبکه سیستم شما است.
زمانهای پاسخ (Response Times): نظارت بر زمانهای پاسخ برای اطمینان از اینکه برنامههای شما استانداردهای عملکرد مورد انتظار را برآورده میکنند، ضروری است. زمانهای پاسخ کند میتواند منجر به تجارب کاربری نامطلوب شود و مشکلات زیرین را که نیاز به رفع سریع دارند، نمایان کند.
فرکانس پیادهسازی (Deployment Frequency): پیگیری نرخ پیادهسازی کد جدید میتواند دادههای بینشبخشی در مورد کارایی لوله CI/CD شما ارائه دهد. فرکانس بالای پیادهسازیها معمولاً نشاندهنده متدولوژی قوی DevOps است، در حالی که فرکانس پایینتر ممکن است چالشهای احتمالی در دوره توسعه را برجسته کند.
دسترسپذیری و زمان آنلاین (Uptime and Availability): اطمینان از دسترسپذیری بالا و کاهش زمانهای خرابی برای حفظ رضایت کاربران ضروری است. با پیگیری معیارهای زمان آنلاین و دسترسپذیری، سازمانها میتوانند قابلیت اطمینان سرویس را بهبود بخشند و فرصتهای بهبود را شناسایی کنند.
حجم تراکنشها (Transaction Volumes): پیگیری حجم تراکنشهای پردازششده توسط برنامه شما به شما این امکان را میدهد که الگوهای استفاده را تحلیل کرده و نیازهای مقیاسپذیری را ارزیابی کنید. همچنین، به شناسایی مشکلات عملکردی که ممکن است در دورههای اوج تقاضا بروز کنند، کمک میکند.
عواملی که باید هنگام انتخاب ابزار مانیتورینگ DevOps در نظر بگیرید
در اینجا فهرستی سریع از برخی از ملاحظات مهم هنگام انتخاب ابزارهای مانیتورینگ برای تیمهای DevOps ارائه شده است:
- مانیتورینگ یکپارچه: بهجای داشتن نمای جداگانه که اغلب منجر به شکافهای دید میشود، به دنبال راهحلی باشید که به شما امکان مشاهده اکثر اجزا به طور همزمان را بدهد.
- رابط کاربری دوستانه: ابزاری را انتخاب کنید که دارای داشبوردهای قابل تنظیم و ویژگیهای تعاملی باشد تا بتوانید اطلاعات را مطابق با نیازهای خود سفارشی کنید.
- کشف خودکار: این ویژگی فرآیند جستجو و شناسایی داراییهای IT در شبکه را خودکار میکند و زمان و تلاش را صرفهجویی میکند. بسیاری از ابزارهای مانیتورینگ این ویژگی را ارائه میدهند، اما همه آنها این ویژگی را ندارند.
- معیارها، رویدادها و ردیابیهای توزیعشده در زمان واقعی: تحلیلهای زمان واقعی از دادههای نظارتی به محض در دسترس بودن استفاده میکند و به شما امکان میدهد خطاها را قبل از تبدیل شدن به مشکلات پرهزینه شناسایی کنید.
- تحلیل علت ریشهای: این رویکرد به شما این امکان را میدهد که علت اصلی مشکل را شناسایی و رفع کنید، بهجای اینکه صرفاً به درمان علائم بپردازید و سپس آنها دوباره ظاهر شوند.
- دورههای نگهداری داده: اکثر ابزارهای مانیتورینگ DevOps دارای محدودیتهای خاصی برای نگهداری دادهها هستند. دوره نگهداری طولانیتر هزینه بیشتری دارد، اما میتواند به شناسایی الگوهای سلامت سیستم کمک کند، بهویژه زمانی که مشکلات بهطور گاه به گاه رخ میدهند.
- AIOps و یادگیری ماشین: برخی از ابزارهای مانیتورینگ DevOps از فناوریهای AI برای بهبود جستجو، پاسخگویی و حل مسائل فنی استفاده میکنند و زمان را کاهش داده و بهرهوری را بهبود میبخشند.
- مانیتورینگ استفاده از منابع و هزینههای مرتبط: هزینه اکنون به معیار اول برای اکثر سازمانها تبدیل شده است، زیرا 32٪ از بودجههای ابری هدر میرود. با این حال، بیشتر ابزارهای هزینهسنجی بهطور کلی و نادرست عمل میکنند و عمدتاً هزینه کل و میانگین را ارائه میدهند، نه جزئیات مانند هزینه به ازای هر مشتری، هزینه به ازای هر پیادهسازی، یا هزینه به ازای هر درخواست.
با در نظر گرفتن این عوامل، در اینجا برخی از بهترین ابزارهای مانیتورینگ DevOps برای حمایت از بهبود مستمر آورده شده است.
بهترین ابزارهای مانیتورینگ DevOps بر اساس دستهبندی
ابزارهای DevOps مزایای متعددی ارائه میدهند:
- خودکارسازی وظایف تکراری: این ابزارها میتوانند وظایف تکراری را خودکار کنند و به مهندسان این امکان را میدهند که تنها بر روی مهمترین وظایف، مانند رفع تهدیدات امنیتی یا انتشار ویژگیهای پیشرفته سریعتر برای افزایش رقابتپذیری سازمان، تمرکز کنند.
- کاهش خطای انسانی: با کاهش خطای انسانی، کدهای قابل اعتمادتری را سریعتر منتشر کنید.
- بهبود فرآیند توسعه نرمافزار: با استفاده از یکپارچگی مداوم و توسعه مداوم (CI/CD).
- بهینهسازی هزینهها: ترکیب این مزایا به بهینهسازی هزینهها کمک میکند.
در اینجا برخی از بهترین ابزارهای مانیتورینگ که میتوانید از آنها استفاده کنید، بر اساس دستهبندیهای مختلف DevOps آورده شده است.
ابزارهای مانیتورینگ DevOps منبع باز
برای کسانی که دارای منابع مالی محدود هستند یا به دنبال راهحلهای نظارت مداوم قابل تنظیم هستند، نرمافزارهای منبع باز میتوانند مفید باشند. در اینجا چهار نمونه از آنها آورده شده است:
1. Nagios
Nagios یک راهحل مانیتورینگ DevOps پیشرفته است که نظارت جامعی برای سرورها، برنامهها و شبکهها فراهم میکند. این ابزار قادر به نظارت بر هر دستگاهی که دارای آدرس IP است، بوده و میتواند خدمات مختلف سرور مانند POP، SMTP، IMAP، HTTP و Proxy را بر روی سیستمهای Linux و Windows نظارت کند. همچنین نظارت بر برنامهها را نیز تسهیل میکند و به نظارت بر عواملی مانند استفاده از CPU، فضای swap، حافظه و معیارهای بار پردازش میپردازد.
این ابزار به صورت رایگان قابل دانلود است و دارای یک رابط کاربری وب شهودی است و از بیش از 5,000 یکپارچگی برای نظارت بر سرورها پشتیبانی میکند. نسخه منبع باز آن، که به نام Nagios Core شناخته میشود، به صورت رایگان در دسترس است، در حالی که نسخه تجاری آن، Nagios XI، قابلیتهای مانیتورینگ خود را به زیرساخت، برنامهها، شبکه، خدمات، فایلهای لاگ، SNMP و سیستمهای عامل گسترش میدهد.
2. Prometheus
Prometheus به صورت رایگان قابل دانلود است و شامل مجموعهای از ابزارهای مانیتورینگ است که در محیط DevOps مفید واقع میشود. این ابزارها دارای قابلیتهای هشداردهی، امکان ذخیرهسازی دادههای سری زمانی بر روی دیسکهای محلی یا در حافظه، و تجسم دادههای گرافیکی از طریق Grafana هستند. علاوه بر این، Prometheus پشتیبانی گستردهای از انواع یکپارچگیها، کتابخانهها و انواع معیارها ارائه میدهد.
3. Zabbix
Zabbix به عنوان یک جایگزین برتر برای Nagios، مانیتورینگ بلادرنگ برای ترافیک شبکه، خدمات، برنامهها، محیطهای ابری و سرورها را فراهم میآورد. این ابزار میتواند هم به صورت محلی و هم در فضای ابری مستقر شود. نسخه جدید آن، Zabbix 5.4، بهبودهایی در مانیتورینگ توزیعشده، دسترسپذیری بالا و مجموعهای گسترده از معیارهای مانیتورینگ ارائه میدهد که به شما امکان میدهد قابلیتهای مانیتورینگ خود را در فضای پویا و متغیر DevOps گسترش دهید.
4. Monit
برای کسانی که به دنبال یک راهحل مانیتورینگ جمعوجور برای سیستمهای Unix هستند، Monit انتخابی عالی است. این ابزار به شما امکان میدهد فرآیندهای دیمون، بهویژه آنهایی که در هنگام راهاندازی سیستم از /etc/init/ شروع میشوند، از جمله خدماتی مانند Apache، sshd، SendMail و MySQL را مانیتور کنید. Monit قابلیتهایی برای شناسایی خطا و ارسال اعلانهای هشدار فراهم میآورد و همچنین فایلها، دایرکتوریها و فایلهای سیستم محلی را مانیتور میکند. علاوه بر این، میتوان از آن برای نظارت بر محیطهای ابری، میزبانها و سیستمها، شامل پروتکلهای اینترنتی مختلف (مانند HTTP و SMTP) و همچنین پیگیری استفاده از CPU و حافظه و میانگین بار سیستم استفاده کرد.
ابزارهای مانیتورینگ جامع DevOps
چندین پلتفرم ویژگیهای گستردهای برای مشاهده و مانیتورینگ DevOps ارائه میدهند. با تجمیع نیازهای مختلف مانیتورینگ در یک راهحل واحد، این منابع جامع از حقیقت، شکافهای دید گرانقیمت را کاهش داده، فرآیندها را سادهتر میکنند و هدررفتهای غیرضروری را برطرف میسازند.
5. Datadog
تیمهای DevOps بهطور فزایندهای به Datadog جذب شدهاند به دلیل قابلیتهای جامع مشاهدهپذیری و ویژگیهای مؤثر تحلیل ریشهای مشکلات آن. این پلتفرم به کاربران این امکان را میدهد که اطلاعات مانیتورینگ سیستم را در محیطهای مختلف، از جمله تنظیمات محلی و زیرساختهای ابری متنوع مانند سیستمهای خصوصی، عمومی، هیبریدی و چندابری، جمعآوری، ارزیابی و منتشر کنند.
این تطبیقپذیری، Datadog را به گزینهای قوی برای برنامههای سازمانی تبدیل کرده است. این پلتفرم که بر پایه معماری Go ساخته شده، بهطور یکپارچه با ارائهدهندگان ابری بزرگ مانند AWS، Azure و GCP یکپارچه میشود. علاوه بر این، برای کسانی که به نظارت بر تجربههای دیجیتال علاقهمند هستند، Datadog با دامنه وسیعی از دستگاهها و سیستمعاملها سازگار است و ویژگی مدیریت هزینههای ابری نیز ارائه میدهد.
با این حال، برخی از کاربران Datadog نگرانیهایی درباره هزینههای بالا مرتبط با این سرویس ابراز کردهاند که به بررسی چندین جایگزین مقرونبهصرفه و توانمند دیگر منجر شده است.
6. New Relic
New Relic بهعنوان یک گزینه محبوب بهجای Datadog به دلایل مختلف شناخته میشود. این ابزار، ردیابی خطاهای جامع، شناسایی دقیق ناهنجاریها و مانیتورینگ پیشرفته برای کانتینرها، از جمله Kubernetes را ارائه میدهد. علاوه بر این، New Relic امکان اشکالزدایی کد بهصورت بلادرنگ را بدون نیاز به نمونهبرداری فراهم میکند.
در واقع، New Relic بهعنوان یک پلتفرم کامل مشاهدهپذیری عمل میکند که شامل همه چیز از مانیتورینگ زیرساخت و عملکرد برنامه (APM) تا سرورلس و نظارت بر کاربران واقعی (RUM) میشود. علاوه بر این، پایهگذاری آن بر روی OpenTelemetry سازگاری با بیشتر ابزارها و یکپارچگیهای موجود در تکنولوژی فعلی یا آینده شما را تضمین میکند.
برای استفاده از New Relic، باید عامل New Relic را بر روی سرورها یا دستگاههایی که میخواهید نظارت کنید، نصب کنید. با این حال، لازم به ذکر است که New Relic به اندازه برخی از دیگر گزینهها، بهویژه در زمینه امنیت و رعایت مقررات، تمرکز ندارد.
7. Dynatrace
فراتر از ارائه مشاهدهپذیری جامع برای DevOps، Dynatrace بر امنیت IT از طریق مجموعهای از ابزارهای DevSecOps تأکید زیادی دارد. این پلتفرم با استفاده از اتوماسیون هوشمند، به محافظت از برنامههای ابری در حین اجرا میپردازد و بهطور مؤثر تدابیر امنیتی را به خطوط لوله CI/CD شما ادغام میکند.
با ویژگیهایی مانند تحلیل آسیبپذیریهای اجرایی و حفاظت از برنامه، Dynatrace به کاهش خطر آسیبپذیریهای روز صفر کمک میکند. تیم DevOps قادر است بهطور مداوم تهدیدات برنامه را شناسایی، ارزیابی و کاهش دهد، مانند حملات تزریق فرمان و SQL. علاوه بر این، Dynatrace نظارت سطح سازمانی بر KPIهای تجاری، پلتفرمی برای توسعه برنامههای سفارشی و نقشهبرداری سیستمی بلادرنگ و متنی ارائه میدهد.
با این حال، کاربران ممکن است نیاز به صرف زمان برای یادگیری و بهینهسازی پلتفرم داشته باشند و ساختار قیمتگذاری آن میتواند پیچیده باشد.
8. LogicMonitor
LogicMonitor بهعنوان یک پلتفرم مشاهدهپذیری جامع و بدون نیاز به عامل، بهطور ویژه برای برنامههای DevOps طراحی شده است. مانند دیگر راهحلهای مانیتورینگ پیشرو، این پلتفرم اطلاعات بلادرنگ را در زمینههای مختلف، از جمله زیرساخت و عملکرد وبسایت ارائه میدهد. این پلتفرم ابری میتواند در عرض چند دقیقه مستقر شود، بهطور آسان مقیاسپذیر است و به نظارت ترکیبی، شامل محیطهای ابری و محلی، میپردازد.
علاوه بر این، LogicMonitor قابلیتهای عمیقتری برای نظارت بر سیستمهای ذخیرهسازی ابری، هایپر-کنورژند و سنتی ارائه میدهد. برای سازمانهایی که امنیت استراتژیهای دورکاری خود را در اولویت قرار میدهند، ویژگیهای نظارت بر شبکههای دور و شبکههای تعریفشده با نرمافزار (SD-WAN) LogicMonitor گزینهای مناسب بهشمار میآید.
علاوه بر این، LogicMonitor از امنیت دادهها در هنگام انتقال و ذخیرهسازی اطمینان حاصل میکند، کنترلهای دسترسی مبتنی بر نقش (RBAC) را پیادهسازی میکند و از رمزنگاری TLS برای افزایش حفاظت استفاده میکند.
ابزارهای مانیتورینگ اپلیکیشن، شبکه و زیرساخت
ابزارهای زیر راهحلهایی نزدیک به “تماماً در یک” برای مانیتورینگ مداوم ارائه میدهند.
9. Sensu by Sumo Logic
رویکرد “مانیتورینگ بهعنوان کد” Sensu مجموعهای جامع از ویژگیها را ارائه میدهد، از جمله بررسی سلامت، مدیریت حوادث، قابلیتهای خودترمیم، هشداردهی و مشاهدهپذیری متنباز در محیطهای مختلف. کاربران میتوانند جریانهای کاری مانیتورینگ را از طریق فایلهای پیکربندی اعلامی تعریف کنند که این امکان را برای اشتراکگذاری آسان میان تیمهای مهندسی فراهم میآورد.
این روش مشابه کد، امکان مرور، ویرایش و کنترل نسخه دقیق را فراهم میآورد. علاوه بر این، Sensu Go برای مقیاسپذیری طراحی شده و بهطور یکپارچه با دیگر ابزارهای مانیتورینگ DevOps مانند Splunk، PagerDuty، ServiceNow و Elasticsearch ادغام میشود.
10. Splunk
Splunk امکانات مانیتورینگ مداوم را ارائه میدهد که به سازمانها این امکان را میدهد تا بر چرخه حیات کامل اپلیکیشن نظارت کنند. این پلتفرم نظارت واقعی بر زیرساختها، همراه با قابلیتهای تحلیل و عیبیابی برای محیطهای محلی، چندابری و هیبریدی را فراهم میآورد. همچنین، Splunk شامل هشدارهای زمان واقعی، دیدگاه جامع در سراسر استک، نظارت بر Kubernetes، ابزارهای تجسم، گزینههای مقیاسپذیری و اتوماسیون فرآیندهای مانیتورینگ است که همه در یک رابط کاربری یکپارچه جمعآوری شدهاند.
علاوه بر این، جامعه آنلاین پررنگ Splunk، متشکل از بیش از ۱۳,۰۰۰ کاربر فعال و بیش از ۲۰۰ ادغام، بهعنوان منبعی عالی برای پشتیبانی و سفارشیسازی عمل میکند.
11. ChaosSearch
برای کسانی که ترجیح میدهند از سطلهای ذخیرهسازی Amazon S3 یا Google Cloud Storage برای ذخیرهسازی بکاند استفاده کنند، ChaosSearch فرآیند جمعآوری، تجمیع، خلاصهسازی و تحلیل متریکها و لاگها را ساده میکند. این پلتفرم به شما امکان میدهد تا تریگرها و هشدارها را تنظیم کنید و اطمینان حاصل کنید که مهندسان بهطور فوری از طریق اعلانها در مورد ناهنجاریها مطلع میشوند، در حالی که بر روی اجزای مختلف زیرساخت مانند سرورها، متعادلکنندههای بار و خدمات نظارت میکنند.
علاوه بر این، ChaosSearch قابلیتهای نظارت بر Kubernetes و کانتینرهای Docker را نیز ارائه میدهد. علاوه بر پشتیبانی از ایزولاسیون مبتنی بر ذخیرهسازی در Amazon S3، این پلتفرم همچنین SSO و RBAC را برای حفاظت بهبود یافته دادهها فراهم میآورد.
12. Sematext
Sematext یک راهحل جامع مانیتورینگ ارائه میدهد که برای تیمهای DevOps طراحی شده است و به آنها امکان میدهد تا لاگهای بکاند و فرانتاند، متریکهای عملکرد، APIها و سلامت کلی محیطهای محاسباتی خود را نظارت کنند.
علاوه بر این، این پلتفرم مانیتورینگ کاربران واقعی، دستگاهها، شبکهها، کانتینرها، میکروسرویسها و پایگاههای داده را نیز تسهیل میکند. کاربران میتوانند مدیریت لاگ، مانیتورینگ مصنوعی و تنظیم تریگرها و هشدارها را پیکربندی کنند. با داشبوردهای Sematext، کاربران میتوانند دادهها را به طور مؤثر مشاهده کرده و بینشهای عملی استخراج کنند.
13. Elastic Stack (ELK)
مهندسان میتوانند با استفاده از Elastic Stack بهطور مؤثر دادهها را از منابع مختلف ذخیره، جستجو و تحلیل کنند. کاربردهای ELK شامل لاگها، SIEM (مدیریت اطلاعات و رویدادهای امنیتی)، نقاط انتهایی، متریکها، آپتایم و APM (مانیتورینگ عملکرد اپلیکیشن) بههمراه مانیتورینگ امنیتی است. ELK از سه جزء اصلی تشکیل شده است: Elasticsearch، Logstash و Kibana.
Elasticsearch قابلیت دریافت داده از هر منبع و در هر فرمت را فراهم میکند که سپس توسط Logstash در سمت سرور پردازش میشود. در عین حال، Kibana وظیفه نمایش و بهاشتراکگذاری دادههای پردازششده و ذخیرهشده را بر عهده دارد. از جایگزینهای قابلتوجه میتوان به LogicMonitor، New Relic، Dynatrace، DataDog، Sumo Logic و BMC Helix Operations Management اشاره کرد.
ابزارهای تجمیع داده و غنیسازی بین دامنهای
این دسته شامل موج جدیدی از ابزارهای AIOps است که از روشهای هوش مصنوعی و یادگیری ماشینی برای بهبود دادههای تلهمتری استفاده میکنند. ابزارهای AIOps با جمعآوری، تحلیل و گزارشدهی خودکار دادههای گسترده از منابع مختلف، به شناسایی مشکلات در سیستم سازمانی شما کمک میکنند.
14. Big Panda
الگوریتمهای همبستگی رویداد در BigPanda فرآیند تجمیع، غنیسازی، و همبستگی هشدارها را در زیرساختها، محیطهای ابری و برنامههای کاربردی مختلف سادهسازی میکنند. این فرآیند با ادغام چندین هشدار در یک حادثه جامع، نویز هشدارها را به حداقل میرساند. علاوه بر این، توزیع هشدارها از طریق کانالهای موجود مانند سیستمهای تیکتینگ، ابزارهای همکاری و مکانیزمهای گزارشدهی را تسهیل میکند.
15. Planview Hub (قبلاً Tasktop Integration Hub)
Planview Hub به تیمهای DevOps این امکان را میدهد که ابزارهای مختلف مهم در فرآیند تحویل نرمافزار را یکپارچه کنند و نیاز به مدیریت جداگانه آنها را از بین ببرند. این ویژگی به خصوص برای کسانی که ترجیح میدهند همه چیز، از جمله Git و فرآیندهای تضمین کیفیت کد، را در یک پلتفرم واحد تجمیع کنند، بسیار مفید است.
Planview Hub دارای تعداد زیادی کانکتور از پیش ساخته شده است که یکپارچهسازیهای بدون نیاز به کدنویسی را به سادگی و به سرعت ممکن میسازد. این قابلیت از طیف وسیعی از یکپارچهسازیها پشتیبانی میکند و گردش کارها را از مخازن Git محبوب به پلتفرمهایی مانند Jira، Azure DevOps، ServiceNow و Jama خودکار میکند.
بر خلاف یکپارچهسازیهای نقطه به نقطه سنتی، Hub از یکپارچهسازی مبتنی بر مدل استفاده میکند که باعث میشود راهاندازی سریعتر، نیازهای نقشهبرداری کمتر و زمان کمتری برای نگهداری یکپارچهسازیها صرف شود.
16. Librato (که اکنون بخشی از SolarWinds AppOptics است)
از زمان راهاندازی خود، Librato بهمنظور تسهیل مانیتورینگ مقیاسپذیر و افزونهای از دادههای سریهای زمانی طراحی شده است. مرحله اولیه شامل ارسال دادهها به Librato از طریق یکی از یکپارچهسازیهای آماده موجود است، یا میتوانید بهصورت مستقیم دادهها را به API RESTful ارسال کنید.
با ایجاد داشبوردها، میتوانید متریکهای خود را از طریق نمودارها مشاهده کنید و دادههایتان را فیلتر کنید تا مشکلات خاص را شناسایی کنید. همچنین، میتوانید هشدارهایی برای متریکهای حیاتی تنظیم کنید تا از سلامت خدمات خود مطلع بمانید. اعلانها میتوانند از طریق ایمیل، چت، یا سرویس ترجیحی شما برای ارسال اعلانها ارسال شوند.
Librato با Rails 3.x یا Rack، و همچنین برنامههای مبتنی بر JVM و زبانهای برنامهنویسی مختلف دیگر سازگار است. علاوه بر ایجاد نمودارها و فضاهای کاری سفارشی، کاربران میتوانند رویدادهای یکبار مصرف را نیز اضافه کرده و هشدارهای مبتنی بر آستانه تعریف کنند.
همچنین، با استفاده از دسترسی چندکاربره، عکسهای فوری نمودارهای PNG، لینکهای خصوصی Spaces و یکپارچهسازی با پلتفرمهایی مانند Slack، HipChat و PagerDuty، امکان همکاری بهبود مییابد.
ابزارهای مانیتورینگ سلامت خدمات تجاری
تاریخاً، تیمهای DevOps بیشتر بر جنبههای مهندسی تمرکز داشتند تا تأثیر فعالیتهایشان بر نتایج مالی. با این حال، یک روند رو به رشد در میان تیمهای DevOps دیده میشود که تمرکز خود را به مانیتورینگ وبسایتها، برنامههای موبایل، کاربران نهایی و متریکهای واقعی کاربران (RUM) معطوف میکنند، که توسط بهینهسازی هدایت شده توسط مهندسی ایجاد شده است. در ادامه چندین ابزار ارائه شده که میتوانند در بهبود تلاشهای بهینهسازی شما مفید باشند:
17. Akamai mPulse
Akamai mPulse ابزاری است که به شما امکان میدهد با استفاده از دادههای واقعی کاربران، به بینشهای لحظهای دست پیدا کنید و رفتار کاربران را با عملکرد تجاری خود ارتباط دهید. این ابزار اطلاعات جامعی از بیش از 200 متریک تجاری و عملکردی را مستقیماً از مرورگرهای کاربران جمعآوری میکند. این دادهها برای شناسایی علل اصلی مشکلات تأخیر و کاهش درآمد در تمامی بازدیدهای صفحات تحلیل میشود.
شما میتوانید متریکهای عملکردی مانند استفاده از پهنای باند و زمان بارگذاری صفحات را جمعآوری کنید، همچنین شاخصهای تجاری مانند تعداد سفارشها، نرخ بازگشت (bounce rates)، و نرخ تبدیل را بررسی نمایید.
گزارشهای لحظهای از فعالیت کاربران بلافاصله پس از دریافت اولین بیکن mPulse در دسترس خواهند بود. داشبورد mPulse دارای ویجتهایی است که جزئیات را بر اساس بخشهای مختلف، از جمله توزیع پهنای باند، دستهبندی صفحات، مکانهای جغرافیایی و انواع مرورگرها نمایش میدهد.
در صورت تمایل، سازمان شما میتواند داشبوردهای سفارشی ایجاد کند تا دادهها را به شکلی که بهترین نیازهای شما را برآورده میکند، تنظیم نماید.
18. Sumo Logic
Sumo Logic به عنوان یکی از پیشروهای ارائهدهنده خدمات نرمافزاری (SaaS) در زمینه تحلیل لاگ، عملیات تجاری و مانیتورینگ امنیتی شناخته میشود که با استفاده از فناوریهای هوش مصنوعی و یادگیری ماشین تقویت شده است. این پلتفرم با داشبوردهای آماده و قابلیتهای عیبیابی مبتنی بر هوش مصنوعی، به کاربران امکان میدهد تا بهطور جامع فعالیتهای مربوط به فرآیندهای کسبوکار خود را مشاهده، تحلیل و پاسخ دهند.
علاوه بر این، Sumo Logic شامل راهحلهای مدیریت امنیت اطلاعات و رویدادهای ابری (SIEM) و ارکستراسیون، اتوماسیون و پاسخ به تهدیدات (SOAR) است که به محافظت از دادهها و بارهای کاری شما کمک میکند. با توجه به اینکه IBM تخمین میزند هزینه یک نقض داده میتواند تا 4.5 میلیون دلار برسد، تمرکز Sumo Logic بر امنیت ابری برای سازمانها در هر اندازهای مفید است.
به طور کلی، Sumo Logic به عنوان یک پلتفرم کامل نظارتی عمل میکند که شامل ویژگیهایی برای برنامهریزی ظرفیت و پیشبینی است. این پلتفرم همچنین از نظر مقیاسپذیری نسبت به برخی از رقبای خود برتری دارد. با تجمیع دادهها از زیرساختهای شما، برنامهها، عملیات تجاری و کاربران نهایی در یک پلتفرم واحد، دیدی جامع از محیط IT خود به دست میآورید. با این حال، مهم است که توجه داشته باشید Sumo Logic برای استقرارهای محلی (on-premises) طراحی نشده است، برخلاف گزینههایی مانند Datadog و Sematext.
19. BMC Helix Operations Management
BMC Helix Operations Management به منظور بهبود دید در محیطهای ابری هیبریدی توسعه یافته است. این ابزار اتوماسیون، AIOps، داشبوردهای تعاملی، تحلیل لاگها، مدیریت رویدادها و گردشکارهای شهودی را در یک پلتفرم واحد ادغام میکند.
BMC Helix Operations Management در ارائه بینشهای مربوط به عملیات لحظهای برنامههای کانتینری شده شما برتری دارد. با نظارت بر این فعالیتها، میتوانید بینشهایی در مورد نحوه تأثیر چالشهای فنی بر رضایت مشتری و به تبع آن، عملکرد مالی خود به دست آورید.
علاوه بر این، این ابزار قابلیتهایی مانند تحلیل علت ریشهای و تحلیل پیشبینیکننده را ارائه میدهد که به شما امکان میدهد مسائل را به طور مؤثر برطرف کرده و منافع تجاری خود را محافظت کنید.
ابزارهای کنترل کد منبع DevOps
DevOps با همکاری تیمهای مختلفی که به طور همزمان بر روی کد کار میکنند، تعریف میشود و این امکان را فراهم میآورد که بهروزرسانیهای سریع و منظم به برنامهها انجام شود. این بهبود مداوم منجر به تغییرات زیادی در پایگاه کد میشود. برای تیمها ضروری است که اطمینان حاصل کنند که تمام مهندسان از یک نسخه واحد از کد منبع استفاده میکنند. ابزارهای مدیریت کد منبع این فرآیند را تسهیل میکنند.
20. Git (GitHub، GitLab، و BitBucket)
تعدادی از تیمهای DevOps از Git به عنوان سیستم مدیریت کد منبع ترجیحی خود استفاده میکنند. ساختار محلی branching، جریانهای کاری متنوع، و قابلیتهای staging به محبوبیت آن نسبت به گزینههای دیگری مانند Mercurial، CVS، Helix Core، و Subversion کمک کرده است.
در حالی که Git به صورت محلی نصب میشود، GitHub به تسهیل همکاری از راه دور و مدیریت کد منبع توزیعشده در فضای ابری کمک میکند. علاوه بر این، Bitbucket و GitLab نیز برای برنامههای کاربردی سازمانی مناسب هستند.
مانیتورینگ خطوط لوله و پیکربندی CI/CD
Jenkins، RedHat Ansible، Bamboo، Chef، Puppet، و CircleCI از جمله ابزارهای برجسته CI/CD در حال حاضر هستند. با مانیتورینگ خطوط لوله CI/CD مرتبط با این ابزارها، میتوانید دید بیشتری در تمام محیطها، از جمله توسعه، تست، و تولید به دست آورید.
21. AppDynamics
ابزارهای مختلفی برای دستیابی به دید کد در سطح کد وجود دارد. به عنوان مثال، میتوانید Jenkins را با Prometheus برای جمعآوری و ذخیره دادهها، و Grafana برای تجسم دادهها ادغام کنید. بهعلاوه، ممکن است به دنبال یک راهحل جامع برای مانیتورینگ مداوم خط لوله CI/CD خود باشید، مانند AppDynamics یا Splunk.
AppDynamics به شما تلمتری واقعی از متریکهای مشتری و کسبوکار ارائه میدهد، که به شما امکان مانیتورینگ زیرساختها، خدمات، شبکهها و برنامههای کاربردی در محیطهای ابری مختلف را میدهد. این ابزار همچنین بینشهایی در مورد Kubernetes، Docker، و Evolven، همراه با تشخیص علل ریشهای، ساختار قیمتگذاری بر اساس استفاده، و قابلیتهای مانیتورینگ هیبریدی ارائه میدهد.
مانیتورینگ سرور تست
یک مانیتور تست به ارزیابی یک تست جاری پرداخته و بازخورد سازندهای ارائه میدهد. علاوه بر این، نظارت و کنترل پیشرفت تست شامل تکنیکها و عناصر مختلفی است که تضمین میکند تست در هر مرحله به استانداردهای تعیینشده دست یابد. Selenium نمونهای برجسته از ابزاری است که برای نظارت بر پیشرفت تست استفاده میشود.
22. Selenium
Selenium یک چارچوب متنباز و پرکاربرد است که برای اتوماسیون برنامههای وب بهمنظور تست طراحی شده است. با این حال، قابلیتهای آن فراتر از تستهای پایهای است. با استفاده از Selenium WebDriver، میتوانید بهطور مؤثر تستهای بازگرایشی و مجموعهها را اتوماسیون کنید، که امکان انجام تستهای مرورگر بر روی مقیاسهای گسترده و توزیعشده را در محیطهای مختلف فراهم میآورد.
Selenium Grid بهعنوان یک مرکز متمرکز عمل میکند و به شما این امکان را میدهد که تستها را بهطور همزمان بر روی چندین ماشین، سیستمعامل، مرورگر، و محیطهای مختلف اجرا کنید. همچنین، Selenium IDE افزونهای است که برای مرورگرهای Firefox، Chrome و Edge در دسترس است و ضبط و پخش ساده تعاملات مرورگر را تسهیل میکند. گزینههای دیگر برای Selenium شامل ابزارهایی مانند Ranorex و Test.ai هستند.
تجمیع هشدار و مدیریت حوادث
ابزارهای زیادی در سطح سازمانی وجود دارند که میتوانند دادهها را از منابع مختلف تجمیع و تحلیل کنند. در حالی که BigPanda قادر به تجمیع دادهها از منابع متعدد است، PagerDuty گزینهای مؤثر برای تیمهای DevOps است که نیاز به مدیریت نوبت، پاسخ به حوادث، مدیریت رویدادها و تحلیلهای عملیاتی دارند.
23. PagerDuty
PagerDuty به عنوان یک سرویس مدیریت هشدار، به طور مؤثری هشدارها را تجمیع کرده و نویز غیرضروری را کاهش میدهد. با رابط کاربری کاربرپسند و ارائه دادههای منظم، این پلتفرم شناسایی همبستگیهای بین رویدادهای مختلف را تسهیل میکند.
این پلتفرم به راحتی با سیستمهای مانیتورینگ، پشتیبانی مشتری، مدیریت API و ابزارهای مدیریت عملکرد یکپارچه میشود. با پشتیبانی از بیش از 550 ادغام، این امکان را میدهد که تقریباً هر ابزار مانیتورینگ یا مدیریت لاگ که قادر به ارسال تماسهای REST یا ایمیلها باشد، متصل کنید. از جمله ادغامهای قابل توجه میتوان به AppDynamics، Microsoft Teams، AWS، ServiceNow و Slack اشاره کرد که ممکن است از آنها استفاده کنید.
گزینههای جایگزین برای PagerDuty شامل Slack، AlertOps، Splunk On-Call و ServiceNow IT Service Management هستند.
بهترین شیوههای مانیتورینگ در DevOps
در هر استراتژی DevOps، بسیار مهم است که به بهترین شیوههای مربوط به مانیتورینگ توجه کنید تا اطمینان حاصل شود که فرآیند بهطور مؤثر از ابتدا توسعه و پیادهسازی میشود. بیایید به بررسی بهترین شیوههایی که به یک استراتژی موفق مانیتورینگ در DevOps کمک میکند، بپردازیم.
تعیین اهداف روشن
تعیین اهداف واضح برای شناسایی معیارهای مناسب برای پیگیری و ابزارهای مورد نیاز حیاتی است. این اهداف میتوانند شامل بهبود کارایی سیستم، کاهش زمان خاموشی، و به حداکثر رساندن استفاده از منابع باشند.
خودکارسازی
اصل اساسی DevOps حول محور خودکارسازی میچرخد. تلاش کنید تا حد امکان فعالیتهای مانیتورینگ را خودکار کنید. با این کار، احتمال خطای انسانی را کاهش داده، ثبات را ارتقاء میدهید و به تیم خود امکان میدهید تا بر روی ابتکارات استراتژیکتر تمرکز کنند.
پیادهسازی مانیتورینگ پیوسته
مانیتورینگ پیوسته شامل مشاهده در زمان واقعی سیستمها و برنامههای شما است. این استراتژی به شناسایی و حل سریع مشکلات قبل از اینکه بر روی کاربران تاثیر بگذارد، کمک میکند و از توسعه مستمر و روشهای توسعه چابک پشتیبانی میکند.
ایجاد یک محیط همکاری
همکاری بین تیمهای توسعه، عملیات و امنیت را ترویج دهید. با اشتراکگذاری دادههای مانیتورینگ با همکاران، مشکلات میتوانند به سرعت حل شوند و فرهنگ مسئولیتپذیری را تقویت کنند.
استفاده از لاگگذاری و مانیتورینگ متمرکز
اطلاعات لاگگذاری و مانیتورینگ خود را تجمیع کنید تا یک منبع واحد از حقیقت ایجاد کنید. لاگگذاری متمرکز به ادغام دادهها از منابع مختلف کمک کرده و امکان تحلیل جامع و تولید گزارشهای یکپارچه را فراهم میآورد. ابزارهای معمولاً استفاده شده در DevOps برای این عملکرد شامل Elasticsearch، Logstash و Kibana هستند که بهطور مشترک به عنوان ELK Stack شناخته میشوند.
ادغام مانیتورینگ با خطوط لوله CI/CD
ابزارهای مانیتورینگ خود را در خطوط لوله CI/CD خود ادغام کنید تا بازخورد مداوم فراهم کنید. این ادغام به شناسایی سریع مشکلات در حین توسعه کمک میکند و اطمینان حاصل میکند که فقط کد با کیفیت بالا به محیط تولید منتقل میشود. تستهای خودکار و ارزیابیهای مانیتورینگ میتوانند در فرآیند CI/CD ادغام شوند.
اولویتبندی مانیتورینگ امنیتی
مانیتورینگ امنیتی را در جریانهای کاری DevOps خود وارد کنید تا آسیبپذیریها شناسایی و کاهش یابند. به هرگونه دسترسی غیرمجاز، فعالیتهای غیرعادی و رعایت استانداردهای امنیتی توجه داشته باشید.
تنظیم هشدارهای معنادار
اطلاعرسانیهایی را تنظیم کنید تا تیم شما از مسائل فوری مطلع شود. اطمینان حاصل کنید که این اطلاعرسانیها راهنماییهای واضحی در مورد اقدامات مورد نیاز ارائه دهند. هشدارهای آستانهای را برای نظارت بر شرایط خاص و هشدارهای پیشبینیکننده را برای پیشبینی چالشهای احتمالی پیادهسازی کنید.
استفاده از داشبوردها و تجسمها
از داشبوردها و ابزارهای بصری برای ارائه دادههای مانیتورینگ بهطور واضح و قابل دسترسی استفاده کنید. داشبوردها بینشهای فوری از سلامت سیستم، روندهای عملکرد و ناهنجاریها فراهم میآورند. با سفارشیسازی این داشبوردها، تیمها میتوانند بر روی معیارهای مرتبط با نقشهایشان تمرکز کنند.
تمرکز بر تجربه کاربری
در فعالیتهای مانیتورینگ خود، تجربه کاربری را در اولویت قرار دهید. معیارهای متمرکز بر کاربر مانند زمانهای پاسخ، نرخهای خطا و زمانهای عملکرد سرویس را پیگیری کنید. ابزارهای مانیتورینگ واقعی کاربر (RUM) و مانیتورینگ مصنوعی را برای ارزیابی تعامل و سطح رضایت کاربران پیادهسازی کنید.
پیگیری زیرساخت و برنامهها
مانیتورینگ جامع باید شامل زیرساخت و برنامههای شما باشد. مانیتورینگ زیرساخت بر نظارت بر روی سرورها، شبکهها و سیستمهای ذخیرهسازی تمرکز دارد. مانیتورینگ برنامهها بر عملکرد، در دسترسپذیری و تجربه کاربری تأکید دارد. این رویکرد جامع اطمینان حاصل میکند که تمام عناصر زیرساخت شما مورد توجه قرار گیرد.
انجام بررسیها و ممیزیهای منظم
بهطور منظم فرآیندها و ابزارهای مانیتورینگ خود را بررسی و ارزیابی کنید. اثربخشی استراتژی مانیتورینگ خود را ارزیابی کرده، تنظیمات مانیتورینگ را در صورت لزوم تنظیم کنید و از تطابق با استانداردهای صنعتی و بهترین شیوهها اطمینان حاصل کنید. ارزیابی و بهبود مداوم برای حفظ یک سیستم مانیتورینگ مؤثر ضروری است.
موارد استفاده مانیتورینگ در DevOps
شفافیت در هر مرحله از تولید DevOps اهمیت زیادی دارد. این شامل نمای کلی از وضعیت و عملیات درون پلتفرم زیرساخت شما است. علاوه بر این، حتی جزئیترین عناصر ارزش مانند یک خط کد خاص نیز نیاز به توجه شما دارند. در ادامه، به بررسی عملکردهای کلیدی مرتبط با این موضوع میپردازیم.
- بررسی کد (Code Linting): ابزارهای بررسی کد (Linting) کد شما را از نظر انتخابهای سبک، صحت نحو و احتمال خطاها ارزیابی میکنند. این ابزارها همچنین ممکن است به بررسی انطباق با بهترین شیوهها و استانداردهای کدنویسی بپردازند. با استفاده از بررسی کد، میتوانید مشکلات را قبل از اینکه منجر به خطاهای زمان اجرا یا مشکلات دیگر شوند، شناسایی و رفع کنید. علاوه بر این، بررسی کد به حفظ یک پایگاه کد تمیز و یکنواخت کمک میکند.
- عملیات گردش کار Git (Git Workflow Operations): ممکن است هنگامیکه چندین توسعهدهنده به طور همزمان بر روی یک بخش از پروژه کار کنند، تضادهایی در پایگاه کد ایجاد شود. Git ابزارهای مختلفی برای کمک به مدیریت و حل این تضادها، مانند commits و rollbacks، ارائه میدهد. با نظارت بر فعالیتهای گردش کار Git برای شناسایی تضادهای احتمالی، میتوانید از حفظ یکپارچگی و ثبات پروژه خود اطمینان حاصل کنید.
- لاگهای ادغام مداوم (CI) (Continuous Integration (CI) Logs): لاگهای ادغام مداوم (CI) برای ارزیابی موفقیت ساختهای کد و شناسایی هرگونه خطا یا هشدار ضروری هستند. در صورت بروز خطاها، باید منابعی برای تحقیق، رفع عیب و حل مشکل اختصاص دهید. علاوه بر این، مانیتورینگ لاگها میتواند به شناسایی مشکلات احتمالی در پایپ لاین ساخت یا پایگاه کد شما که نیاز به توجه دارند، کمک کند.
- لاگهای پایپ لاین استقرار مداوم (CD) (Continuous Deployment (CD) Pipeline Logs): نظارت بر لاگهای CD میتواند اطلاعات مهمی درباره سلامت و عملکرد پایپ لاین ارائه دهد. با مرور این لاگها، میتوانید مشکلات مربوط به استقرارهای ناموفق را تشخیص داده و چالشهای احتمالی را شناسایی کنید.
- لاگهای تغییرات مدیریت پیکربندی (Configuration Management Changelogs): لاگهای تغییرات مدیریت پیکربندی بینشهای اساسی در مورد وضعیت سیستمها و تغییرات عمده ارائه میدهند. با نظارت بر این لاگها، میتوانید تغییرات دستی و خودکار را پیگیری کنید، تغییرات غیرمجاز را شناسایی کرده و مشکلات احتمالی را به طور مؤثر حل کنید.
- لاگهای استقرار زیرساخت (Infrastructure Deployment Logs): لاگهای استقرار زمانبندی استقرارهای جدید استک را ثبت کرده و نشان میدهند که آیا با شکست مواجه شدهاند یا خیر. این لاگها برای تشخیص مشکلات مربوط به استقرار استک و شناسایی تغییرات غیرمجاز در زیرساخت که ممکن است منجر به شکست شده باشد، ارزشمند هستند.
- instrumentation کد (Code Instrumentation): Instrumentation کد شامل ادغام کد اضافی به برنامه شما برای جمعآوری دادههای مربوط به عملکرد و جریان عملیاتی آن است. با پیادهسازی instrumentation، میتوانید فراخوانیهای استک را پیگیری کرده و مقادیر متنی را مشاهده کنید. تحلیل خروجی از instrumentation کد به شما این امکان را میدهد که کارایی شیوههای DevOps خود را ارزیابی کرده و مناطق نیازمند بهبود را شناسایی کنید. علاوه بر این، میتواند در شناسایی اشکالات و تسهیل فرآیند تست کمک کند.
- ردیابی توزیع شده (Distributed Tracing): ردیابی توزیع شده نقش حیاتی در مانیتورینگ و رفع عیب برنامههای میکروسرویسها ایفا میکند. با کسب بینش در مورد تعاملات بین برنامههای شما، معمولاً از طریق APIها، شناسایی و حل مشکلات سادهتر میشود. علاوه بر این، ردیابی توزیع شده به بهبود عملکرد برنامه با نشان دادن گلوگاههای احتمالی کمک میکند.
- مانیتورینگ عملکرد برنامه (APM) (Application Performance Monitoring): APM به منظور مانیتورینگ عملکرد و در دسترس بودن برنامهها طراحی شده است. این شامل ردیابی زمان پاسخ، شناسایی خطاها، و استفاده از Real User Monitoring (RUM) برای ارزیابی تجربه کاربر نهایی، به همراه سایر قابلیتها است. استفاده از راهحلهای APM به شما این امکان را میدهد که به طور پیشگیرانه مشکلات را شناسایی و حل کنید تا از تأثیر آنها بر روی سیستم کلی جلوگیری کنید.
- مانیتورینگ دسترسی API (API Access Monitoring): مانیتورینگ و مستندسازی دسترسی و ترافیک API به شما این امکان را میدهد که دسترسیهای غیرمجاز و حملات DDoS احتمالی را شناسایی و متوقف کنید.
- مانیتورینگ زیرساخت (Infrastructure Monitoring): مانیتورینگ زیرساخت شامل نظارت بر عملکرد و دسترسی سیستمهای کامپیوتری و شبکهها است. ابزارهای طراحی شده برای مانیتورینگ زیرساخت میتوانند دادههای زمان واقعی در مورد متریکهای مختلف، از جمله استفاده از CPU، ظرفیت دیسک، حافظه و ترافیک شبکه، ارائه دهند. این ابزارها در شناسایی مشکلات مربوط به منابع قبل از ایجاد قطعیها یا مشکلات دیگر مفید هستند.
- مانیتورینگ شبکه (Network Monitoring): مانیتورینگ شبکه شامل نظارت بر عملکرد و دسترسی به یک شبکه کامپیوتری و اجزای مختلف آن است. مدیران شبکه از ابزارهای مانیتورینگ برای شناسایی مشکلات مربوط به شبکه و پیادهسازی اقدامات اصلاحی لازم استفاده میکنند. علاوه بر این، مانیتورینگ شبکه از لاگهای جریان برای شناسایی فعالیتهای مشکوک استفاده میکند.
- مانیتورینگ مصنوعی (Synthetic Monitoring): مانیتورینگ مصنوعی به رویکردی در تست نرمافزار اشاره دارد که از مدلهای مجازی سیستمها و اجزای واقعی آنها استفاده میکند. این روش امکان ارزیابی عملکرد، قابلیت و قابلیت اطمینان را فراهم میآورد، چه تمرکز بر روی اجزای خاص باشد و چه ارزیابی کل سیستم به عنوان یک مجموعه.
چه مواردی را باید در یک پلتفرم مانیتورینگ DevOps جستجو کنید؟
هنگام انتخاب یک راهکار برای مانیتورینگ DevOps، ایدهآلترین سیستم آن است که بهراحتی در جریان کار شما ادغام شود. این به این معنی است که پلتفرم انتخابی باید با ابزارهایی که تیمهای شما در جریان کار توسعه خود استفاده میکنند، از جمله:
- ابزارهای توسعه برنامه
- کنترل نسخه
- خطوط لوله CI/CD
- خدمات و زیرساختهای ابری
- سیستمهای زیرساخت بهعنوان کد
- سیستمهای تیکتینگ و پیگیری مشکلات
- رعایت چارچوبهای نظارتی مناسب
- ابزارهای همکاری و ارتباطات تیمی
پلتفرم ایدهآل نظارت بر DevOps باید دارای یکپارچگیهای داخلی با ابزارهای شما باشد، یا حداقل باید از راهحلهای معتبر شخص ثالث پشتیبانی کند.
ضروری است که هر عضو تیم به دادههای زمان واقعی از پلتفرم نظارت دسترسی داشته باشد تا بتوانند بهطور پیشگیرانه گلوگاهها را شناسایی و برطرف کنند. سیستم نظارتی شما باید تلاشهای خودکار موجود شما را تکمیل کند بدون اینکه مانع آنها شود و همچنین ارتباطات را بهبود بخشد و اقدامات امنیتی و ایمنی را تضمین کند. علاوه بر این، به دنبال گزارشها یا داشبوردهایی باشید که کاربرپسند و قابل دسترسی در تمام سطوح باشند.
این نمایشهای بصری باید دادهها را در قالب یک سیستم گستردهتر بگذارند و شامل نقشههای وابستگی باشند. جریانهای لاگ، چه از منابع ابری و چه محلی، باید بهطور یکپارچه با تمام لایههای تکنولوژی شما ادغام شوند و بهراحتی قابل پیمایش باشند. پلتفرم باید همچنین بینشهایی درباره روندهای تاریخی و ناهنجاریها ارائه دهد و توانایی همبستگی مؤثر رویدادها را داشته باشد.
آینده مانیتورینگ DevOps
عملکرد مانیتورینگ بر DevOps به سرعت در حال پیشرفت است و به نظر میرسد که رشد قابل توجهی را تجربه کند. پیشبینیها نشان میدهد که بازار DevOps تا سال ۲۰۲۶ از ۲۰ میلیارد دلار عبور خواهد کرد و تقاضا برای نظارت مداوم و بهبود شیوههای DevOps در سازمانها به احتمال زیاد کاهش نخواهد یافت. با پیشرفت ابزارهای نظارتی برای DevOps، انتظار میرود که اتوماسیون و یکپارچگی این راهحلها افزایش یابد. پیادهسازی تستهای shift-left بهبود امنیت و کیفیت محصول را به همراه خواهد داشت و به تحول به سمت DevSecOps کمک میکند.
پیشبینی میشود که تیمهای DevOps بیشتری بهسراغ پایپلاینهای جامع و یکپارچه چرخه حیات توسعه نرمافزار بروند که با ابزارهای نظارتی مناسب پشتیبانی میشود. گزارشی از Forrester پیشنهاد میکند که راهحلهای مانیتورینگ DevOps تخصصی، MLOps، CI/CD یکپارچه و پایپلاینهای CD/RA (اتوماتیکسازی تحویل و انتشار مداوم) را تسهیل خواهند کرد و توسعهدهندگان و پلتفرمهای کمکد یا بدون کد را درگیر خواهند کرد. علاوه بر این، انتظار میرود که ابزارهای نظارتی در فضای DevOps به دستگاههای لبه شبکه نیز گسترش یابند.
با توجه به تغییرات سریع در حال حاضر، منطقی است که نتیجهگیری کنیم مانیتورینگ DevOps به تکامل خود ادامه خواهد داد و همکاری میان تیمهای توسعه، بخشهای IT و فضای کسبوکار گستردهتر را در آینده قابل پیشبینی بهبود خواهد داد.



{kind=link}
{kind=link}
{kind=link}